iOS MachineLearning 系列(10)—— 自然语言分析之文本拆解
iOS MachineLearning 系列(10)—— 自然语言分析之文本拆解
本系列的前几篇文章介绍了iOS中有关图像和视频处理的API,视觉处理主要有Vision框架负责,本篇起,将介绍在iOS中Machine Learning领域相关的自然语言处理框架:NaturalLanguage。
1 - 简介
NaturalLanguage是iOS种提供的一种处理自然语言的内置框架,使用它不会使应用的包体积增大,不会为应用带来额外的负担,且可以实现非常强大的语言处理功能。
NaturalLanguage默认支持多种语言,拥有如下能力:
- 检测一段文本所使用的语言。
- 将一段文本按照词组,句子,段落进行拆解。
- 进行词性分析。
- 进行语义分析。
本篇,我们主要介绍其文本拆解能力,及如何使用这些API。
2 - 拆解文本
我们先从一个简单的示例来看如何使用NaturalLanguage框架中的API进行文本拆解。
首先准备一段测试文本,如下:
最近,随着Chat-GPT4的发布,人工智能相关的资讯和话题再次火热了起来😄。
有了人工智能的加持,对人们的生活以及各行各业的工作都将带来效率的极大提升。目前,各种大模型的发布层出不穷。这些大模型虽然功能非常强大(如文本理解,绘图等),但对于个人来说,要跑起这样一个模型来对外提供服务还是比较困难的,其需要有非常强大的算力支持。
这段文案有两个段落组成。我们可以先尝试对其内的单词进行拆解。 使用NLTokenizer来解析文本,定义NLTokenizer实例如下:
1 | let tokenizer = NLTokenizer(unit: .word) |
其参数unit确定要解析的元素类型,枚举如下:
1 | public enum NLTokenUnit : Int, @unchecked Sendable { |
调用如下的方法即可进行拆解任务:
1 | tokenizer.enumerateTokens(in: string.startIndex ..< string.endIndex) { range, attribute in |
在回调block中,如果需要停止解析,返回false即可。解析的结果会将元素属性,所在原字符串中的范围进行返回。其中元素属性结构体定义如下:
1 | public struct Attributes : OptionSet, @unchecked Sendable { |
如果上面定义的3个静态值都没有命中,则表示当前元素只包含简单文本。
showWord方法简单实现如下:
1 | func showWord(string: String, type: NLTokenizer.Attributes) { |
分别以单词,句子和段落的模式进行拆解,效果如下所示:

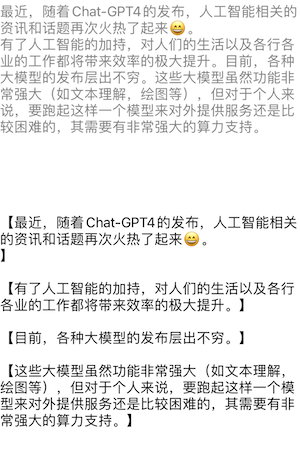
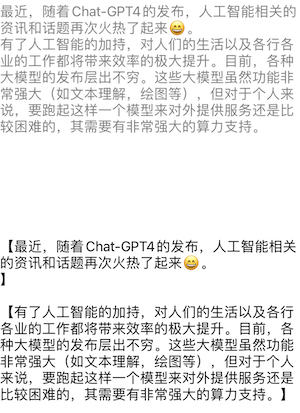
可以看到,整体来说NaturalLanguage对于中文的解析能力还是比较强大的。
3 - 再看NLTokenizer 类
NLTokenizer类专门用来对文本进行拆解,本身比较简单。其中的NLTokenUnit用来设置拆解模式,内部Attributes结构体可以标记出所拆解出的元素所包含的属性。NLTokenizer类本身定义如下:
1 | open class NLTokenizer : NSObject { |
拆解往往是自然语言分析的第一步,通常我们会将长文本进行拆解,之后在对每个元素进行语言类型分析或语义分析,以及词汇的词性分析等,后面的文章会具体再做介绍。